DevOps #2: Enable Unit Tests
7 minute read


Our Unit Test Suite Hurts!
TDD, CI, and DevOps assume that unit tests have the following traits:
- Domain relevant: Test one thing the user cares about and could describe.
- One Way to Fail: Can only fail for one reason, which is its assertion.
- Independent: Execute only the code they verify. You don’t need to update the test if anything else changes.
- Cover Functionality: The set of tests as a whole cover all behaviors of the system. This is bug coverage, not code coverage.
But that’s not realistic in our codebase. Most people find themselves “massaging” one of the rules of good unit testing to make it work.
Therefore, we are left with common issues such as:
- Unit testing isn’t catching the interactions, but integration tests are miserable and mocks miss things.
- The unit test suite takes too long to run, has intermittent failures, and often changing one thing requires updating a bunch of unrelated tests.
- This code has no obvious units. Everything is done in the database / in large methods / in micro-service interactions / in the rules engine.
The answer is to fix the code under test. There is no way to fix the pain by changing the tests, because the test pain is just a symptom of the design. We have to fix the design.
For example, one common Legacy design is the Vase-shaped Method, so named because the indentation looks like the shape of a vase. We want to test the “bulb” (indented part) of the vase. Everything else gets in the way.

There is a simpler design that would do the same thing. That simpler design would be far easier to test. We just need to answer 3 new questions:
- How do I find the simpler design for my system?
- Once I’ve found it, how do I change from my current design to the simpler one?
- Given that I don’t have tests yet, how do I ensure that I don’t break anything while I make this design change?

Fix These 5 Design Flaws Over and Over
Five common design norms account for the vast majority of testing challenges. Every untested codebase repeats 3-5 of these norms in nearly every class and method. They are so common that no one even notices them — they are the “normal way to do things.”
The 5 hard-to-test desgns are:
- Poor Parameter: A method that reads or writes a small amount of data to an annoying dependency. This prevents One Way to Fail.
- Large Privates: A method that calls a non-trivial private method. This prevents Independent.
- Function Call: A method that directly calls other methods which do things we wish to test indepenently. This prevents Independent.
- Micro-method: A method smaller than 2-3 lines, which does nothing that a customer could describe in their domain. This prevents Domain Relevant.
- Long Method: A method more than 8 lines long or that contains more than one paragraph. This prevents One Way to Fail.
This month we’re sending you one short recipe for each untestable design.
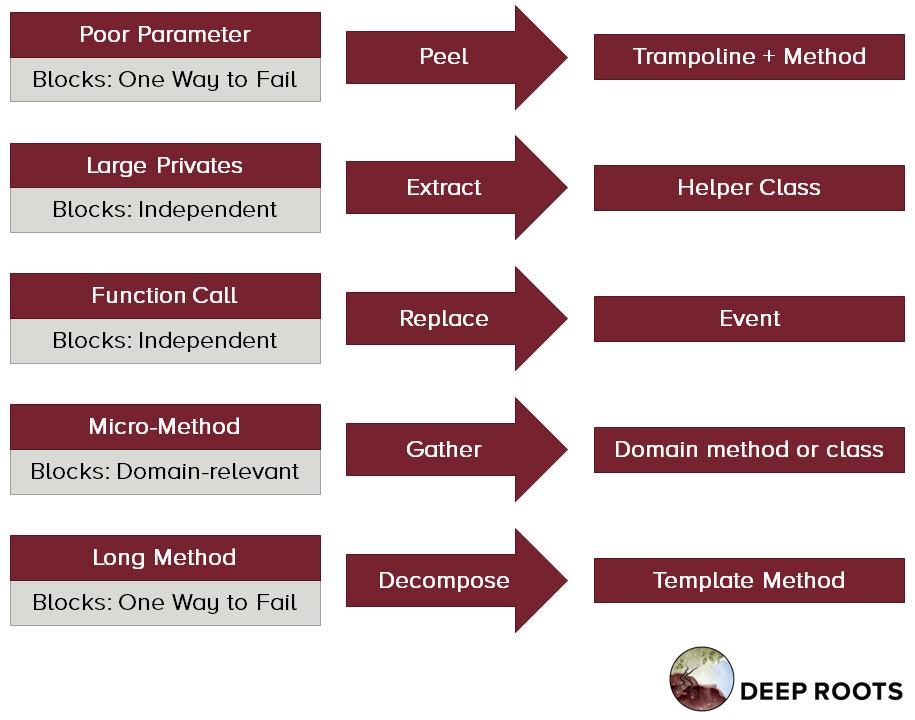
The hard part is seeing the design flaw. Executing each change is simple.
For example, Vase methods arise because of poor parameters. That forces the initial paragraphs that load values to local variables. Over time it is easier to add new functionality to the existing method than to create a new method and handle the parameters. So the vase grows with more paragraphs and function calls. We end up with three kinds of flaws: Poor Parameter, Function Call, and Long Method.
We fix these problems one at a time. Each solution allows us to get one part of the code under a real unit test.
Access the recipe to fix the 5 most common untestable designs, as well as other recipes coming in the future!

Useful Unit Tests… And Better Designs
With practice, we are able to get a long method under test in a couple of hours. Each story we implement can pay to get 1-3 methods under test. Stories cluster, so this focuses our refactoring and testing on the actively-changing code.
Better yet, we are focusing on the root cause and not just the symptom. Our tests are better because our code is easier to work with. This also makes the code easier to work with in other ways. It is easier and faster to extend for new stories. Changes are less likely to introduce bugs, so there will be fewer bugs for our tests to find.
Our tests will cover enough to be useful within a month. We will have good code to put into the DevOps pipeline we started building last month.
Benefits:
- Create unit tests that don’t cause pain when things change.
- Test all of your behavior without integration tests.
- Decrease the time to extend existing code.
- Decrease bugs created when changing existing code.
Downsides:
- Requires looking past the obvious symptom to see the underlying cause. This can create team stresses if some stakeholders are unable to see the underlying cause.

Demo the value to team and management…
Show three things at your sprint demo:
- Example: One checklist and process execution.
- Progress: Progress dashboard.
- Impact: Total time spent on manual and automated processes.
Example: One Method Plus Tests, Before and After
Your goal is to show that the reason the tests are good is because the code is now less terrible. It will be easy to show that the tests are good. The challenge will be to help people see that the code change made it possible.
First show the original code and any tests you had for it. Highlight the design flaws that made it difficult to test. If it has tests, show one and describe the problems tests like this cause, such as false failures and missed bugs.
Now show your final tests. Demonstrate how they meet all of the criteria for good unit tests: they are domain relevant, have one way to fail, are independent, and cover the functionality of the method.
Finally show the new code structure that made these tests possible. Show specific design changes and how that made a set of the tests possible.
Progress: Progress Dashboard
Continue your progress dashboard from last month. Now add a new measure to it: percent of changed code that was already well-tested.
When you work on a story, record any method that you have to change. Also record whether the method was clean or dirty when you first started. A clean method is one that is well-tested by tests that meet the unit test criteria. This means it is factored into reasonably testable design. A dirty method is anything else.
If you need to read a method that is not immediately obvious, use the Insight Loop to read it by refactoring it. This will speed reading and will also change the method. This counts in the above stats.
When the story finishes, count the number of dirty methods, clean methods, and methods that were cleaned during the story. Convert this into a percentage for each category.
Create a scatter-plot of time vs percentage. Plot each percentage for the story on the date it completes. Add this chart to the dashboard.
Expect the chart to start with a high percentage of dirty, then have a widely varied amount of clean and dirty, and eventually stabilize into a steadily-increasing clean line. You should also see a consistent, flat percentage of methods being cleaned.
Impact: Process Savings
Step 1 Track defects back to the story that introduced them. Track this back for at least the prior 2 months to establish a baseline. Include all bugs found in testing or after release. Group all the bugs by the week in which their story completed. Compute three numbers:
- Your testing detection rate — what percentage of bugs slip past your testing process to production.
- Your first fortnight find rate — what percentage of bugs are found in the first 2 weeks after story completion.
- Your average number of bugs created per week.
Step 2 Track the average amount of time you spend reporting bugs, communicating them, triaging them, fixing them, and verifying they are fixed. Total this to get the cost per bug. Multiply this by bugs per week to compute your average extra time lost per week of development.
Step 3 Track the amount of time you spent this sprint making code testable and then testing it.
Step 4 Add a chart that shows numbers for each week. However, these are lagging metrics, so compute it only for the time up to 4 weeks ago. Line it up with the progress chart for the same weeks.
- Extra time lost to bugs from the week.
- Time spent making code testable that week.
- First fortnight find rate that week.
- Testing detection rate that week.