DevOps #4: Extract Components to Edit Independently
9 minute read


Other People Keep Messing with My Code!
I was working with a company that had about 100 teams in the same product. Each had a different purpose, so each changed different code. However, it wasn’t as clean as that makes it sound.
Each team found itself making contributions across a quarter of the product. Each change impacted the work of a few other teams. Each method or class was shared among 2–4 teams — but it was a different 2–4 teams each time.
As a result, each team had to coordinate any change it made, and each coordination involved a different set of collaborators. Any story would change code in several places, so each story required coordinating 3 or more teams. Progress was excruciatingly slow.
Unsurprisingly, integration bugs were common. Testing was good and each commit caused a full-company integration, so at least they were found early. However, they were still plentiful enough to account for a large portion of the total tech budget.
Unowned Code
My team’s code covers lots of the product. But none of it is really mine.
Every team, everywhere
There were two problems:
- My team’s code is scattered across the product.
- Each piece of “my” code is actually shared across teams.
Yes, We Tried Code Ownership
That company attempted to solve both problems by designating code ownership.
Each directory or file could be associated with a designated list of shepherds. Those shepherds attempted to coordinate changes. They maintained overall design consistency. They helped contributors invite the right collaborators to code reviews. They identified when strategic refactorings were needed and got those on the schedules of the various contributing teams.
It helped, but ultimately failed.
Code Ownership is Not Enough
A year later, the program successfully made each coordination experience more efficient. Despite this success, we still had all the problems listed below.
- Lots of integration bugs still happened.
- Stories were “blocked on integration” in one team until another team was ready.
- Code reviews blocked task completion. Teams needed input from another team while the second team was in crunch mode.
- Redesigns would finish in some teams while others didn’t start, leaving the code a mess.
- Or no one would start the redesign, because they didn’t trust that all the other teams would schedule the work too.
Code ownership made coordination more efficient. But we needed a way to make coordination unnecessary.

Extract My Code From Every Method and Class
Here’s an easy step-by-step to successfully claim your code.
- Notice today’s story requires you to change only a part of some method.
- Extract that part.
- Claim that extracted method by putting it into a component.
- Name that component (see recipe for details)
Today’s story will also require some new code. The new code obviously wasn’t needed for prior stories, so has different reasons to change than the prior code. Put it directly into the right component and work towards methods that have only one reason to change.
Now We Can Edit Independently
A method with only one reason to change will be changed by only one team. Managers try to simplify their organizations by giving each team an independent purpose. While each purpose gives many reasons to change code, each reason is intended to align to exactly one team.
When managers discover that their teams have to share reasons to change code, they act to fix the organization. Thus, when code has only one reason to change then only one team will need to change it — and if not, then your manager will fix it.
This month you will transform code so that each method, entity, and class has only one reason to change. Then you will gather this single-purpose code into a component, separate from the rest of the product.
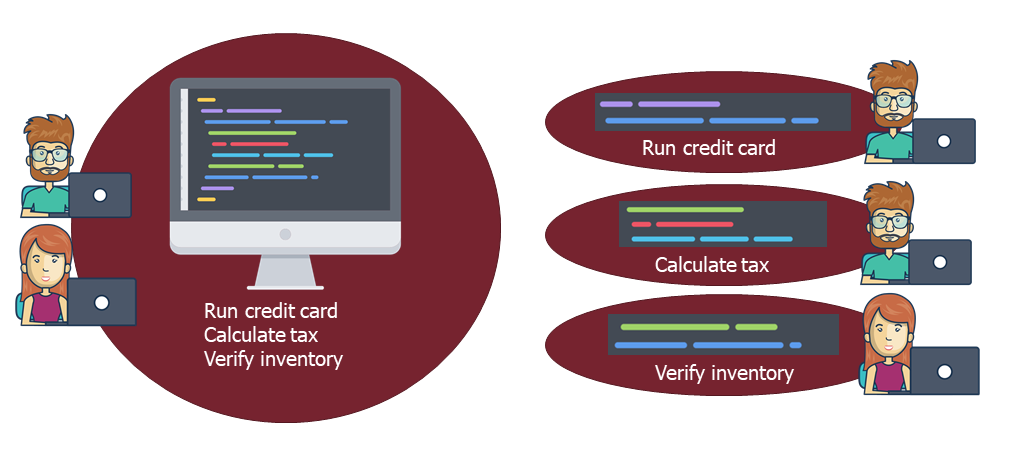
Expect to make several components per team. Make one component for each reason to change code.
Nuance Note: Each story should only change code in one component, but your team may change several components in the same day for different stories.
Components with only one reason to change make things easier:
- You can more easily find the code you need to change for a story.
- It is easier to define a single, clear purpose for each component, which reduces sharing between teams.
- Management can easily move responsibilities between teams as investment levels need to change.
How Small is Too Small?
People often worry about making components too small. Having thousands of tiny components could cause four kinds of problems, but all are preventable.
- Poor Performance — crossing component boundaries might be slow and components may add memory overhead.
- Management complexity — Product Owners, Testers, and Managers struggle enough with breaking down useful functionality into existing product teams and technical chunks. Adding components might make this harder.
- Interaction complexity — the interesting behavior could arise from the interactions between components, rather than being encapsulated inside a component. Interaction complexity would be harder to design and verify.
- Hard to find the right component — it might be hard to find the right code to change for a new story if you have to look in each component.
How to Make Small Components Without the Problems
The first simplification to reduce problems comes from realizing these components exist only to break down code complexity within the team. They make life easier for coders, but don’t even need to be visible to non-coders. Therefore, you can initially implement each component as just a namespace of classes, compiled directly into the main code. Only further extract the ones where the benefits outweigh the costs.
This addresses both the performance and management complexity concerns.
The next simplification arises by focusing on the structure of components. We developers habitually use technical capabilities to separate components - different places in the design or layers in the architecture. However, each change requires crossing these boundaries.
Instead focus on business operations and entities. As businesses change, each story tends to either change one business operation or one set of entities that the business can operate on. The first kind changes code and the second kind changes data. Create entity-focused components that have no code, just data structures. Create operation-focused components that have no data structures, just code. Now each change is localized inside of a single component. This addresses the concern about interaction complexity.
Finally, name each component using the same terms as the customer uses to describe that part of their business. Now story titles and descriptions will literally include component names. This addresses the concern about finding the right code.
The Eight Techniques for Creating Components
There are two basic recipes, one for each kind of component (data and code), and then there are six additional recipes that cover the most common complications.
Split out the code that needs to change for this one story. Put it in a namespace related to the reason it changed, named using terms from the story. That is your independent component.
Access both the basic and additional recipes at extract code to a component with only one reason to change.

Small Components You Can Edit Independently
Your new component will not be complete yet because your product will still have other code related to the needed change. In fact, we will be gathering the scattered code next month! However, the component will have only one reason to change and only your team will need to change it. Even if your team grows and splits, only one of the resulting teams will need to change this component (because of the responsibility change).
Changes to this code will no longer block on other teams. You don’t coordinate for code review, integration, or unit testing. Your stories will stop being “code complete” and start simply being “done.” There are still many levels of independence to go, but you should already see a significant decrease in story duration.
Benefits:
- Pass code review in hours, regardless of other teams’ schedules.
- Complete redesigns without requiring help from other teams.
- Decrease effort by Product Owners in managing dependencies, coordinating schedules, and unblocking stories.
- Create fewer integration bugs.
Downsides:
- Your initial component boundaries will be imperfect. Expect to refactor code in and out until they are right.
- It will take time to get used to reading and debugging smaller methods. Make sure you use good names!

Demo the value to team and management…
Show three things at your sprint demo:
- Example: a new component.
- Progress: chart showing percentage of changes that are in components.
- Impact: decrease in wait times.
Example: one new component
Your goal here is to show how small the change actually is.
First, show the new “component” code in a namespace, and then show the original form of that code before extraction. Demonstrate how little you actually had to change. Explain how that minimizes risk and cost to change.
Also point out that the only difference is code organization. Therefore Product Owners and Managers don’t need to know about these components. It is an internal way that developers are now acting to improve the company without causing problems for others.
Progress: percent of independent changes
First, keep a list of components which are yours. You will need this each week to update your progress chart showing the percentage of changes that happen in the components.
Run a script that performs the following:
Examines all the commits made by anyone on your team in the last week. For each commit, compute the methods it modified and number of lines in each. Compare that list of methods to the namespaces for your components. Compute the percentage of total lines that fell into each of these 4 categories for this week:
- Bad: any kind of change in someone else’s component, or adding lines in non-component code.
- Reduce: changing lines in non-component code.
- Improving: removing lines from non-component code.
- Great: any kind of change in your own component.
Create a percentage “stacked area chart” by week for these 4 values. Your progress is visible as the shift in percentage of work from category 1 towards category 4.
Impact: decreased waiting
Measure how long stories are blocked and how long team members work on wait-style tasks. Examples of blocks include:
- Time for code review - hours between CR sent out and commit going in. Total it up and divide by (4 * number of devs on team) to get the number of team-days waiting.
- Merge or story blocked for integration testing.
- Story blocked to coordinate with a dependency.
- Story done but feature blocked for release until dependency is met.
- Story blocked in planning until other team is also ready to start.
Total up the team-days spent waiting for the week. This will likely exceed the number of days in the week, as the team is waiting on multiple things at once. Show how this wait time decreases over time.
You will likely notice a rapid decrease waiting for code review and integration testing. Decreases in other wait times will be more delayed. Show the waits by category to make the value more visible.