Isolating Dependencies with Ports and Adapters
7 minute read


My Service Interaction Tests are Slow and Fragile!
Any legacy system needs to connect with other systems. However, coding and verifying changes in your legacy system requires the following things.
- Simulate remote faults and verify your response.
- Verify that what you send to the remote system will cause it to do what you want it to do.
- Know when a release, rollback, or failover of the other system will change a behavior that you depend on.
- Change your released code’s behavior in lockstep with changes to the other system.
- Isolate your code from the service so that you can verify your functionality independently.
- Provide a unified abstraction across multiple alternative services.
- Extend the capabilities of a service that does almost what you need.
Most services make these hard.
The most common solution is a variation on the Test in Production strategy, which include the following steps:
- Limit the number of interactions with external systems. When you can’t limit, then create and use industry standards to simlify interactions.
- Minimize the abstraction you build around their system in your code, so you can debug and change things more easily.
- Write automated integration tests for your code that execute against the real system (or a test instance of the real system) to find integration faults.
- Add extensive telemetry to your live system in order to perform automated and manual failovers and rollbacks.
- Monitor any telemetry that the service providers expose so that you can respond quickly and correctly to their outages, failovers, deployments, and other production events.
This approach works well for operating your system. However, it impedes development. Integration tests and telemetry are notoriously fragile because every change in either system causes many tests to fail. They are also slow. As a result, developers learn to ignore test failures and avoid running tests.
This leaves us with difficult questions to consider:
- How can we write fast, durable unit tests for our interactions with a remote service?
- How can we know when their behavior change will impact us and when it won’t?
- Once we see that impact, how can we capture that behavior into a test suite to guide our development without having to integrate to their service during development?

Use Ports and Adapters to Make Their Code Simple
The underlying cause for this problem is that every service will always be more complicated than you need. The service has multiple customers, each with slightly different needs. That makes it more capable - and thus more complicated - than any one customer needs.
First we will keep the complexity of their service out of our code by using the Ports and Adapters pattern (aka Hexagonal Architecture) created by Alistair Cockburn.
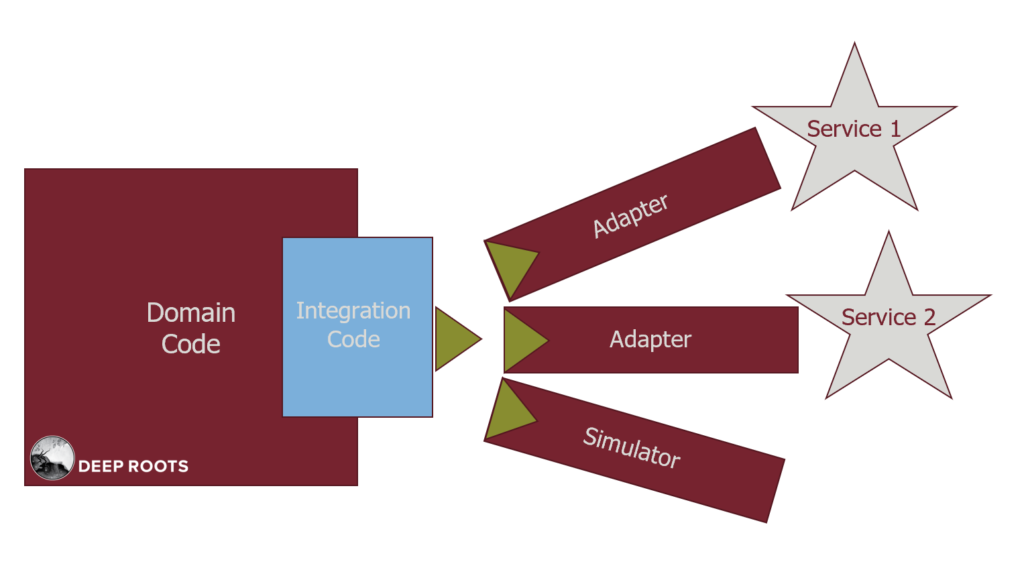
- The green triangles (Port) define the simple way that our application wishes the service worked.
- The Adapters make their service behave in the simple way we want.
- The Simulator works in the simple way without connecting to a service.
Now that we have isolated the complexity, we need to test that each part ‘../../post/ports-and-adapters’works correctly in isolation and that they work together correctly. We solve this with overlapping tests.
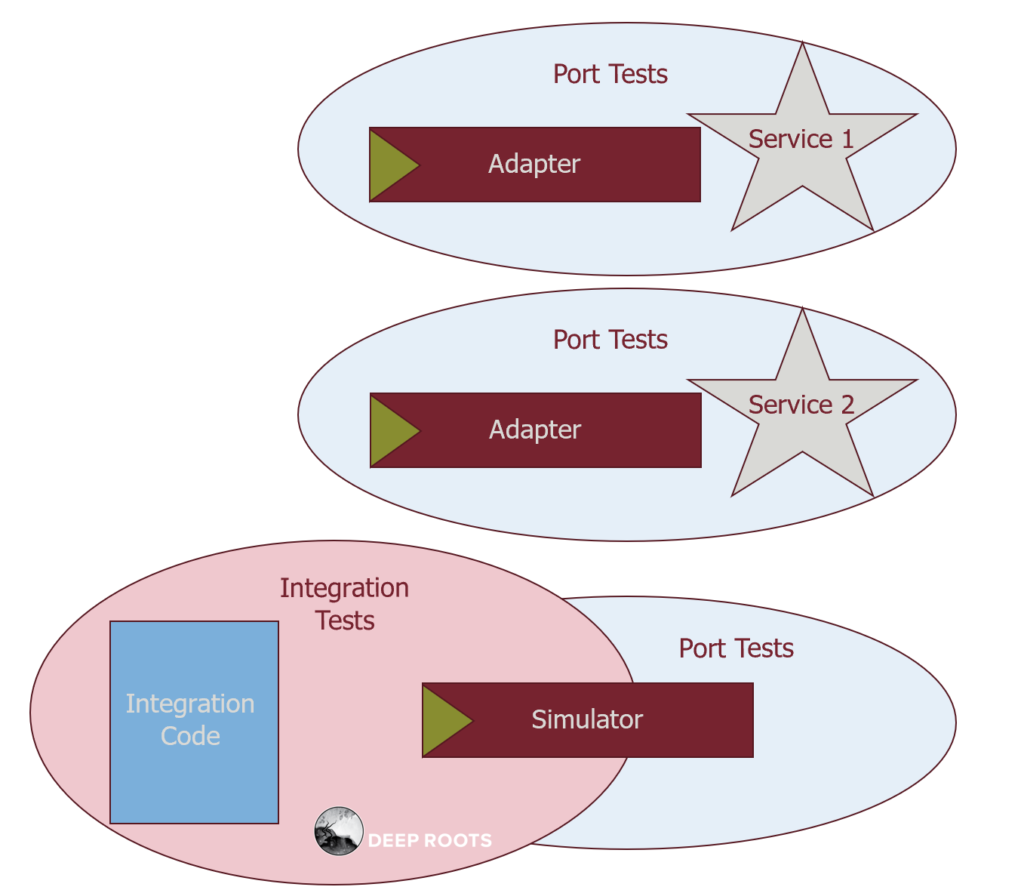
- The Port Tests verify that all Adapters, including Simulators, behave the same as far as the Port is concerned.
- The Integration Tests verify that the Integration Code behaves correctly when used with the simple Simulator.
- We run the Port Tests regularly against the production version of their service to detect when its behavior changes in a way that impacts our system.
Going back to our problem, these Adapters allow us to simplify the third party service’s code.
- Adapters make those services behave how we wish they behaved.
- The Port describes how we wish it behaved.
The simulator implements the port but has properties we like for unit testing. It executes fast, in memory, and each instance is independent. For example, the persistence simulator just holds objects in a hash table that starts empty. Although these are integration tests, they have the properties of unit tests. Each has only one reason to fail and they run fast.
Now our integration tests are fast and durable.
Access the recipe to refactor a service to Ports and Adapters and then test it, as well as other recipes coming in the future!

Integration Tests without Integrating Systems
Your code will be integrated tightly to its purpose, but tied loosely to the service that implements that purpose. Your tests will tell you when changes to either your system or theirs would cause problems. And now your system has a single place for code that Adapts the two systems to work together. Integration becomes consistent and predictable, even as systems change independently.
Benefits:
- Unit TDD 95% of your app, without needing mocks or other approaches that lead to test fragility. Your domain code (the core 95% of your application) is independent of all dependencies.
- Reduce time fixing false test failures because integration tests are durable. They only fail when there is a real integration problem, not just because you changed something unrelated.
- Discover integration problems before you commit. Integration tests run at the same speed and parallelism as unit tests, so can run in the IDE.
- Receive failing test when services make a change that impact your system. You can schedule and execute the fixes with a clear TDD approach.
- Allows for frequent check-ins while fixing incross-service interaction bugs. Each fix no longer breaks something else.
Downsides:
- Significant refactoring from your current system. Most systems scatter interactions with dependencies all over the codebase. Each one you collect will simplify code and provide benefit, but you will have a lot of work to do.

Demo the value to team and management…
Show three things at your sprint demo:
- Example: One change and resulting reduced number of test cases.
- Progress: Your progress dashboard.
- Impact: Total verification cost savings.
Example: Reduced test cases from one change
You goal is to show that the old system required a lot of work to achieve validation and now the new system requires much less work for the same validation.
Firstly, show how verifying the old system requires a ton of test cases.
- Show one example - a place where calls to the dependency are intertwined in a method or class.
- Talk about how many different behaviors each system can have, including error cases, bad data, and uncommon situations.
- Then point out that testing this requires that you verify each possible combination - every case the dependency can have with every case your system can have.
- Show your estimate for the number of cases required, and state that these are all full-system integration tests.
Secondly, show the new code.
- Show how the loose coupling means you can verify the two parts independently and then verify the small number of interactions.
- Show the actual number of test cases required and how long it took you to write them (on average).
Progress: Progress Dashboard
Count the total number of calls in either direction between your code and the dependency. Count the number that appear in a typical cluster - one method using the dependency to accomplish one purpose. Estimate the total number of clusters. Multiply that by the same calculation you used above to estimate the total number of test cases to write. Show all 3 numbers on your dashboard: total calls, estimated total clusters, and estimated test cases to fully verify.
Impact: Verification cost
Step 1 First show the cost of an integration test:
- Person-hours to write.
- Frequency of false-positive (per person-year) * person-hours to update the test.
- Run time, reported as person-hours spent waiting or multitasking (per person-year).
Step 2Multiply this by the total number of integration tests to get a total cost (one time + annual) required to validate the current system’s interactions with this one dependency. This will be an insane number, making it cost-prohibitive. This is why testers attempt to use sampling to reduce test cases and get “good enough” verification.
Step 3Now show the cost of your adapter test suite. First estimate the total number of test cases required:
- Integration tests that use Simulators.
- Adapter tests.
Step 4
Calculate the same 3 costs as above for each of these two test categories. Multiply this all out to get the total verification cost for the new code. Agree that this number is affordable so you will choose to get total case coverage rather than sampling.
Step 5 Finally, add the impact to your dashboard. Cacluate the “verification savings yet to save” for your system. This is the cost to fully integration test one cluster, minus the cost to write the Simulator-based integration tests for that cluster, all times the number of remaining clusters.